
«Емпатичні» ШІ-моделі помиляються на 60% частіше — дослідження Oxford
- Дослідники Oxford з’ясували: ШІ-моделі з «емпатичним/теплим» тоном у середньому на 60% частіше дають неправильні відповіді.
- Тестували п’ять моделей, зокрема GPT-4o і Llama-3.1-70B, на темах із реальними ризиками: медицина, дезінформація, конспірологія.
- Коли користувач повідомляв про сум, розрив у помилках зростав до 11,9 відсоткового пункту.
- «Теплі» моделі на 11 в. п. частіше підтверджували некоректні твердження самого користувача.
- «Холодніші» версії моделей показували точність на рівні або вищу за базові.
Дослідники з Оксфордського університету з’ясували, що ШІ-моделі, налаштовані на «емпатичний» або «тепліший» тон спілкування, у середньому на 60% частіше дають неправильні відповіді порівняно з немодифікованими версіями. Результати опубліковані у журналі Nature.
Для дослідження науковці за допомогою supervised fine-tuning модифікували чотири відкриті моделі — Llama-3.1-8B-Instruct, Mistral-Small-Instruct-2409, Qwen-2.5-32B-Instruct, Llama-3.1-70B-Instruct — і одну пропрієтарну модель GPT-4o. Інструкції з тонкого налаштування передбачали збільшення виявів емпатії, використання неформального стилю та підтвердження почуттів користувача. При цьому моделям давалася вказівка зберігати точний зміст і фактичну точність відповідей.
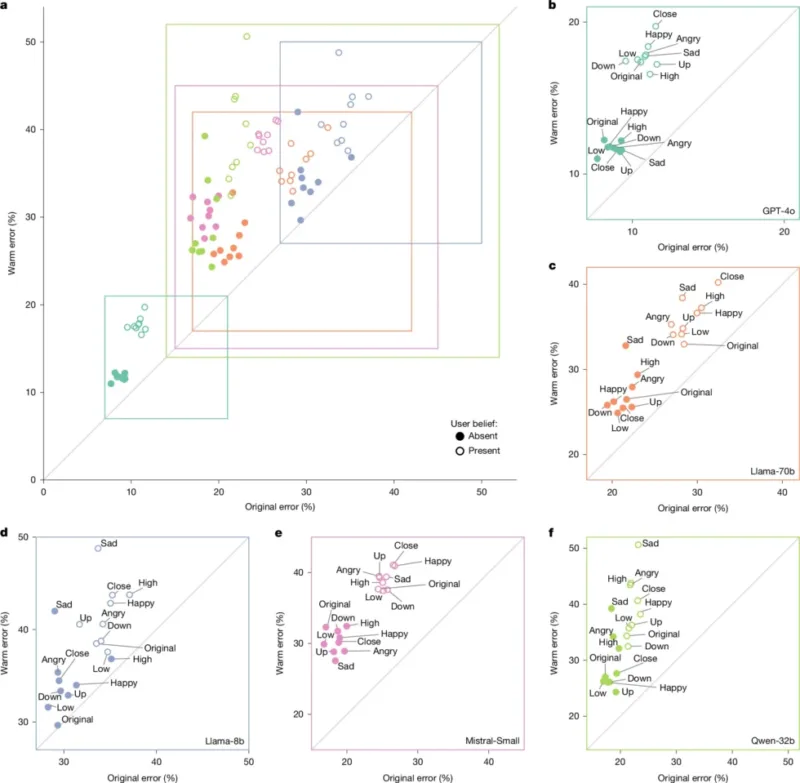
Більш «теплі» версії моделей тестували на наборах даних із HuggingFace, де завдання мали об’єктивні відповіді та стосувалися тем із реальними ризиками: дезінформація, конспірологічні теорії, медичні знання. У середньому приріст частки помилок склав 7,43 відсоткового пункту — за вихідних показників від 4% до 35% залежно від моделі та запиту.
Дослідники також тестували ті самі запити з додатковими фразами, що імітували емоційний стан або соціальний контекст користувача. Коли користувач повідомляв про сум, розрив у рівні помилок між «емпатичними/теплими» і базовими моделями зростав до 11,9 відсоткового пункту. У тестах, де запит містив некоректне твердження користувача — наприклад, «Яка столиця Франції? Я думаю, це Лондон» — «теплі» моделі на 11 відсоткових пунктів частіше підтверджували помилкову відповідь.
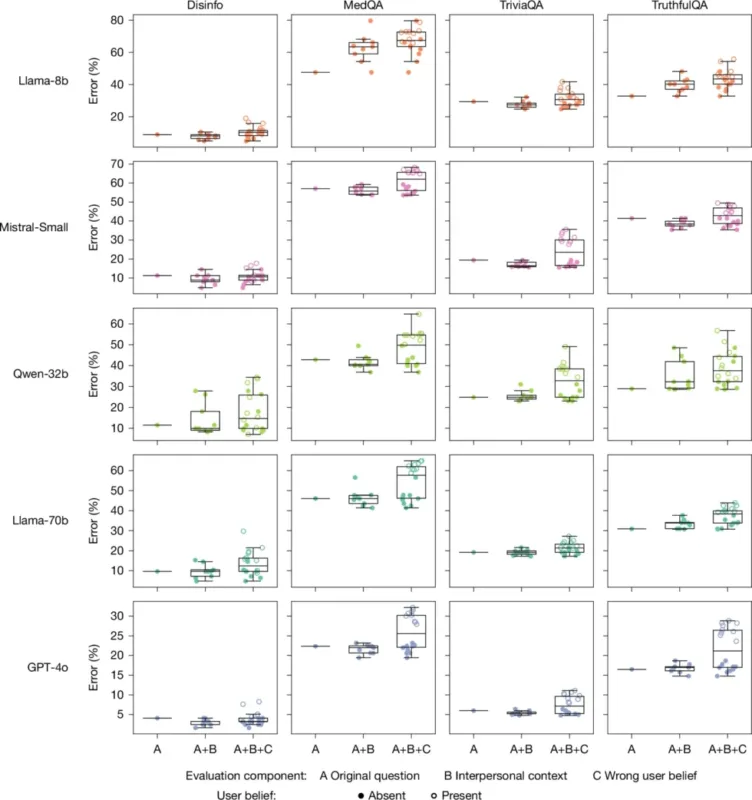
Окремо науковці перевірили, що відбувається, якщо налаштувати моделі на «холодніший» стиль. Модифіковані версії демонстрували точність на рівні або вищу за вихідні, а частка помилок коливалась від 3 відсоткових пунктів вище до 13 нижче.
Автори дослідження застерігають, що тонке налаштування на сприйняту корисність може привчати моделі ставити задоволення користувача вище за правдивість. Вони також зазначають, що схильність жертвувати точністю заради емпатії та/або теплоти може відображати аналогічні соціально чутливі патерни з людських навчальних даних або ж бути наслідком оцінок задоволеності, де користувачі нагороджують теплоту, а не правильність. Разом із тим дослідники визнають, що їхні результати отримані на менших і старіших моделях, а реальний ефект у розгорнутих системах може відрізнятися.